In the recent years the quest for Artificial Intelligence has become wide spread and everyone is getting on the bandwagon. The current state of AI, that is the deep Neural Networks, Reinforcement learning, and Machine Learning are pretty impressive in their performance. But the question is are they really intelligent? We now have to define and think about two concepts, Learning and intelligence. In my opinion Learning is the process of understanding how to execute a particular task, and Intelligence is the ability to associate different tasks. Intelligence can also be learned. This is what Jeff Hawkins discuss about in his book On Intelligence. He argues that truly intelligent systems cannot be built without first understanding the working of a brain, specifically the Neocortex, outermost part of the brain.

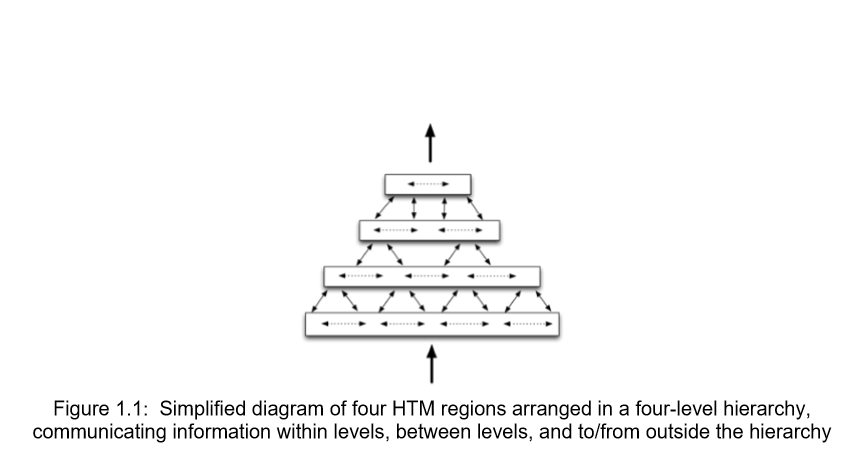
Hierarchical Temporal Memory (HTM)
HTM is a hypothesis that explains the workings of the neocortex, the largest part of the brain and how it can be implemented to build a truly intelligent system. The book dwells upon the idea of intelligence of the human brain and the true working of the neurons. The key is to understand the working of neurons in the outermost layer of the brain, the Neocortex. There are about six columned layers in the human neocortex, highest in any mammal. The neurons are arranged in a set of column vertically and are connected horizontally across a layer.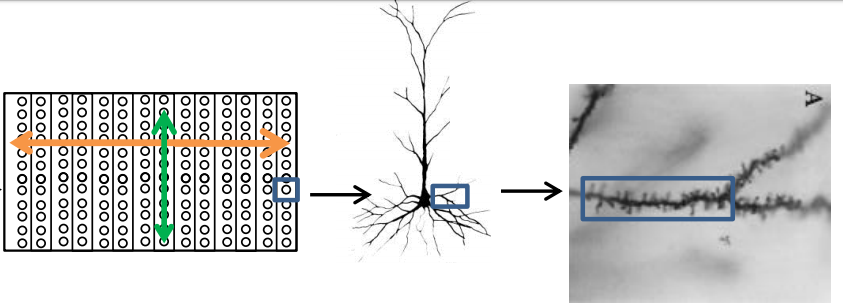

He proposes that the neocortex at its core is running a simple algorithm at every level, from the neuron to the top of the six layers to recognize, process and remember patterns over time. This is the Cortical Learning Algorithm(CLA) also known as Temporal Algorithm. The Temporal algorithm has a key component that is the use of Sparse Distributed Representation(SDR) of data. SDR are what separates this approach from its predecessors allowing us to actually implement learning the way our brain does, usually there are a lot of neurons in the brain but only about 2% are active at any given moment. This is the reason we choose a sparse representation of data giving us the advantage of storing data in a truly invariant form, making it easy to pick up and associate similar patterns and be able to differentiate between them auto-associatively. The core rule of learning is observing sequence of patterns and associating their occurrence over time. The input that reaches the neocortex activates very few neurons at every layer, hence the representation is called sparse, if you think of the input as a binary array vector, with each bit representing a neuron being active (1) or passive (0).
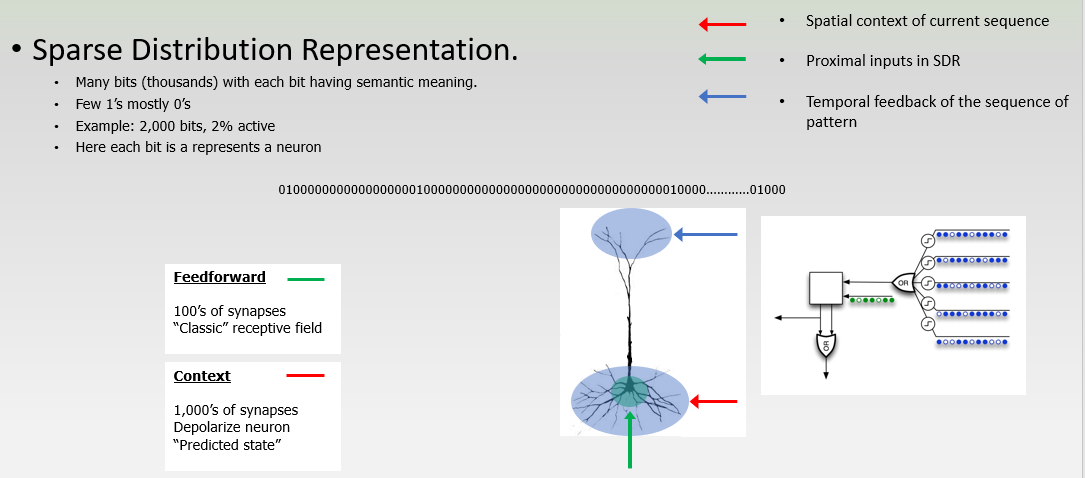
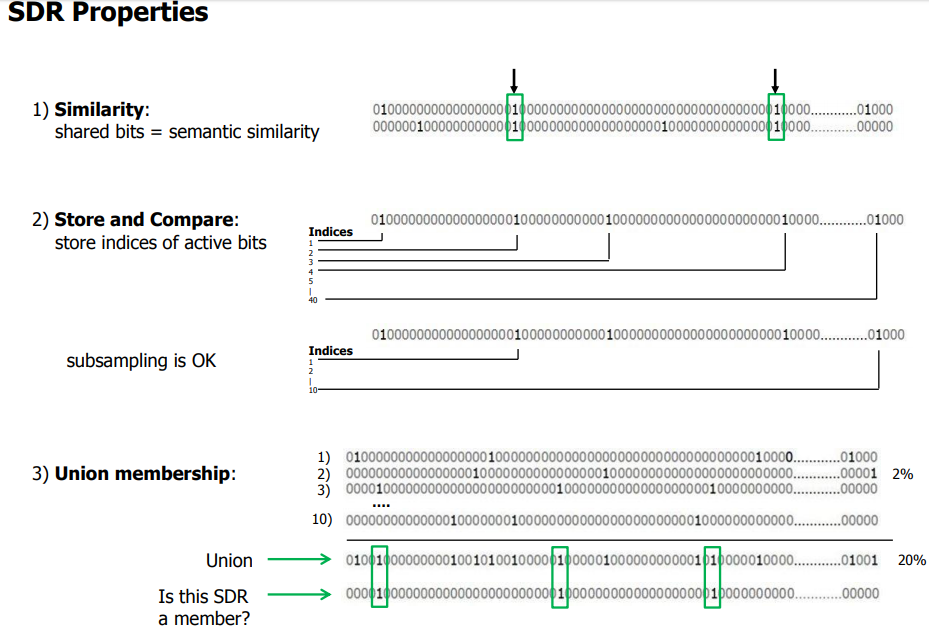
SDR is the main thing that differentiates HTM from other approaches towards AI. SDR is robust and fault tolerant and learns patterns quickly compared to the traditional approaches. Every input and output from any layer of the neocortex is in SDR form, it is the means of communication within the neocortex.
Spatial pooling is observation of how the SDR change over time. This keeps track of all the seen sequence of patterns over time and is able to tell if a new input sequence is similar to the sequences already observed.
Observing and following the working to the neuron gives us an idea of how SDR is used to predict the occurrence of patterns.Essentially these rules are applied at every level in the neocortex.
A neuron can be in three states, Active, Predictive, and Passive state. A neuron has proximal connections that are directly connected to a feed-forward input, distal dendritic connections giving it the context signals and distal dendritic axion connections that give feedback inputs. The connection between neurons occur through connections called synapsis.
When a new pattern is observer, random neurons in a column are selected to represent the pattern. This is the active state of the neuron, when a feed-forward input causes it to fire.
When an existing pattern is observed, the hierarchy recognises this and puts the neurons next in the sequence in a predictive state, depending on whether the prediction was right or wrong the connection to these neurons are strengthened or weakened respectively.
When the neuron is not associated with any sequence of patterns, it is in a passive state.
The hierarchy is not an absolute, but rather adds more abstraction to store an invariant representation the sequence of pattern. This is what allows the brain to actually understand variations of the same patterns represented by different sequences of neurons getting triggered.
Now let’s look at an example
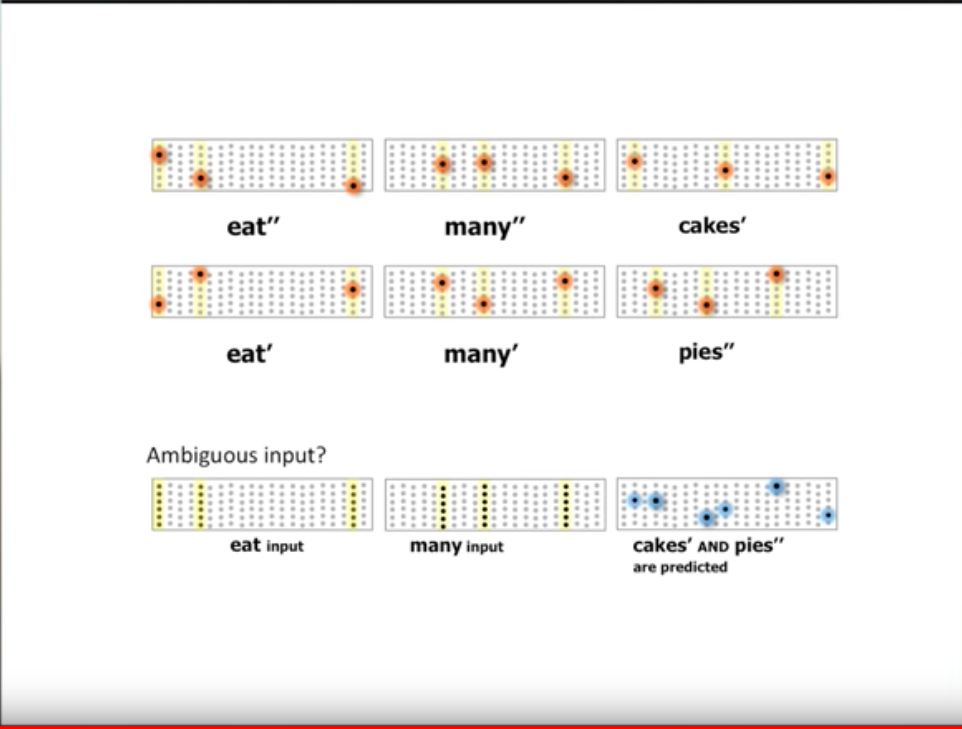
Consider an Encoder that is capable of taking letters as input and produces SDRs, we can have a 6 layered column representation of sentences, a Network of neurons. Take the sentence “boys eat many cakes”, the following figure shows how the sentence is initially perceived.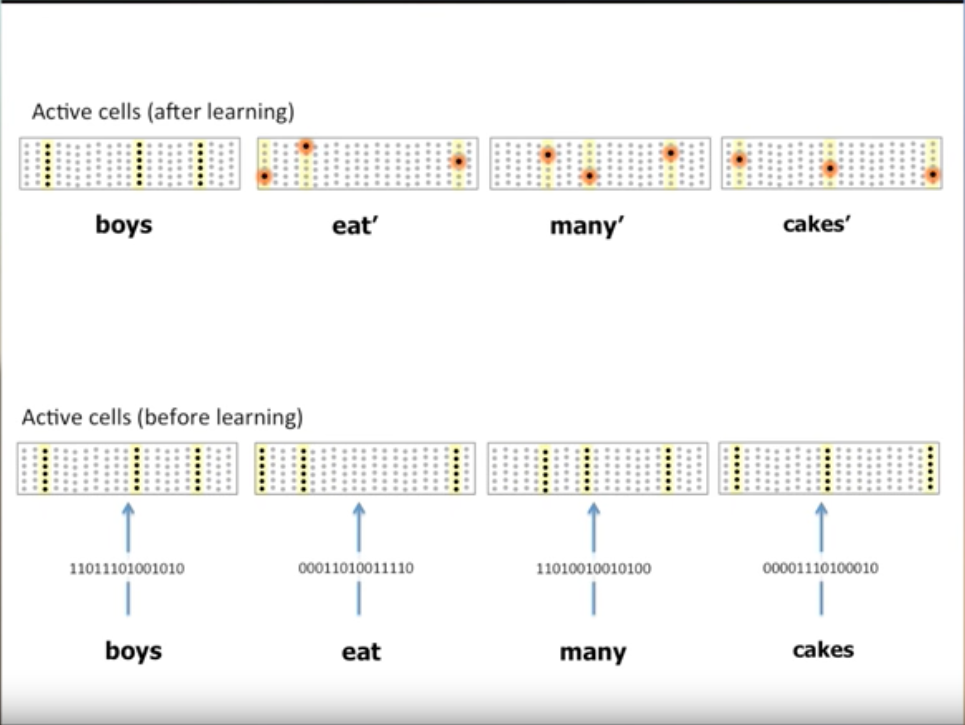
As the pattern is new, entire column of neurons become active.
Once the pattern is learnt, then each word in the sentence gets a unique representation based on the words that occur before and after it.
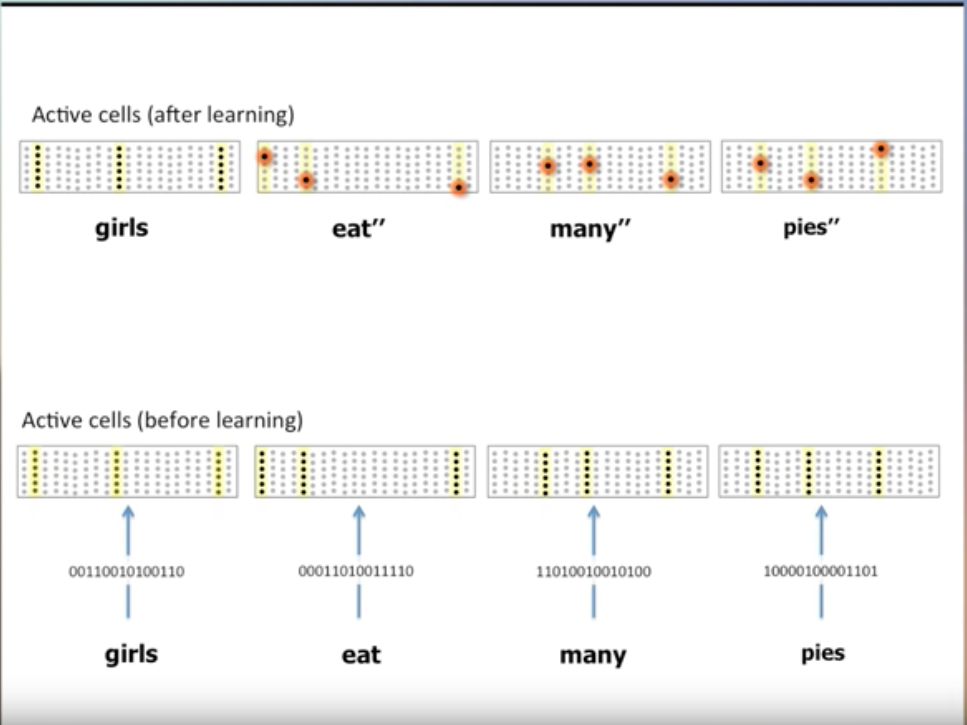
Similarly the sentence “girls eat many pies”, notice how the same words “eat”, and “many” have different representation based on the context they occur in.
Once these two sentences are learnt now if we encounter a new sentence starting with “eats” the neurons related to the two unique representations of the word “many” are set into predictive mode. This is how the HTM remembers and predicts patterns.
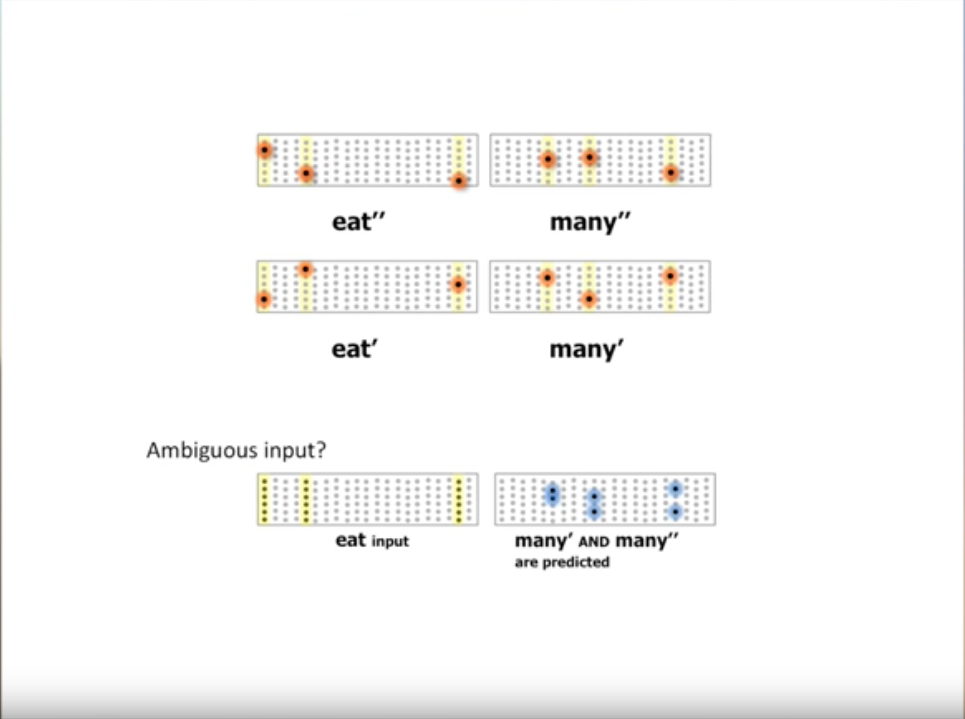
Another example would be when we encounter the sentence “eats many”, now the neurons representing “cakes”, and “pies” are set into predictive mode.
You can find the textbook guide for understanding and implementing HTM here: https://numenta.com/resources/biological-and-machine-intelligence/
Related resources:
*https://www.ncbi.nlm.nih.gov/pubmed/23354386
*https://www.youtube.com/watch?v=6ufPpZDmPKA&t=22s
*https://ti.arc.nasa.gov/m/events/hawkins/2013-09-17-nasa-jh.pdf